Symbolica documentation for getting started, symbolic expressions, numerical evaluation, pattern matching, and APIs in Python and Rust.
Numerical integration is an important tool in many fields. Often integrals are of such complexity that exact integration is impossible. The basic idea of numerical integration is that the integrand function is divided into small boxes. Then each box is sampled many times to get an estimate of how the average value of the integrand in that box. By multiplying the average with the size of the box, an estimate of the integral of that box is obtained. Then the values of all boxes are summed to arrive at an estimate of the integrand.
For example, take the integral:
\[
F(x,y) = \int_{x=0}^1 dx \int_{y=0}^1 dy f(x,y)
\]
where \(f(x,y)\) is any black-box function defined on the unit square. If we split the \(x\) dimension in 10 and the \(y\) dimension as well, we need \(10^2 = 100\) boxes.
The Vegas algorithm
The number of boxes required for a decent evaluation scales exponentially with the dimension (i.e., integration variable). In the example above, where we choose to split each dimension in 10, we would require \(10^{10}=10000000000\) boxes for an integration over 10 variables. This requires too much memory.
The Vegas algorithm treats each dimension separately and partitions each dimension into \(n\)bins (tuneable in Symbolica). Samples are taken from the grid by sampling a floating point number \(x\) between 0 and 1 per integration variable. Then the corresponding bin \(i\) is found by searching for the bin that satisfies \(i/n < x < (i+1)/n\).
After sampling from this grid, based on the sampled values, the measures integrand evaluations are stored in the bin. Based on this, we can estimate the variance per bin. Now, we can update the boundaries of each bin, making them no longer uniformly distributed, but to align them with the variance. This is called grid adaptation.
An example for the integrand
\[ \int_{x=0}^1 dx \sin(2 \pi x) \]
is given here (with only 10 bins for clarity):
The grid starts out uniformly, but then adapts to concentrate around the peaks. Since each bin is sampled with equal probability, regions of the integrand that are denser in bins will be sampled more often. Note that although the largest variance may seem to be in the first bin now, where the integrand changes from \(0\) to \(0.8\), the average value of this region is \(0.4\). In the bin next to it, the average value is \(0.9\), so any variation in that region will have a much larger impact on the integral.
Let us integrate the sine function \(\sin(x)\) with Symbolica and with the Vegas algorithm on the domain \([0,\pi]\) (integrating the function on \([0,2\pi]\) is numerically much harder, since the integral yields 0). The easiest way is to use the integrate function that takes a black-box integrand function. We create a 1-dimensional continuous grid NumericalIntegrator.continuous(1) which samples between 0 and 1. We want to do a maximum of 10 grid adaptations and do a 1000 samples per iteration to train the grid on. We stop when the error reaches 0.1%.
from math import sin, pifrom symbolica import NumericalIntegrator, Sampledef integrand(samples: list[Sample]): res = []for sample in samples: res.append(sin(sample.c[0] * pi))return resavg, err_, chi_sq = NumericalIntegrator.continuous(1).integrate(integrand, show_stats=True, max_n_iter=10, n_samples_per_iter=1000, min_error =1e-4)
Note that the integrand function is called with a list of 1000 samples and should return a list of 1000 integrand evaluations. This is done for efficiency, to prevent overhead from Python.
Symbolica will always sample points on a unit hypercube \(\vec{x} \in [0, 1]^D\). Let us imagine that the integral you want to compute is actually on the unit circle instead of the unit square:
\[
\int_{r=0}^1 dr \int_{\phi=-\pi}^{\pi} d\phi r^2 \sin \phi
\]
We can use the polar coordinate relations:
\[
x = r \cos \phi, \quad y = r \sin \phi
\tag{1}\] to write
This transformation changes the hypervolume (area in 2D) of the original hypercube. This change in volume, relating \(dx, dy\) to \(dr, d\phi\) is called the Jacobian. Using Equation 1, we can compute it:
For some integrations we are interested in the indefinite integral \(\int_{-\infty}^{\infty}\). The variable transformation used for this is called a conformal map. Two example are \(x \rightarrow \alpha \ln(\frac{x}{1-x})\) and \(x \rightarrow \alpha (\frac{1}{1-x} - \frac{1}{x})\), where \(\alpha\) is a tuneable constant.
Discrete grids
The quality of a numerical integration can be drastically improved by using knowledge about the integrand. For example, you may know that the integral is separable into easier integrals. Or perhaps you know that the enhanced regions of an integral are separable using techniques such as multi-channeling. For these cases Symbolica has a feature in the form of nesting discrete grids.
Let us consider the case where a complicated integrand is the sum of two integrand:
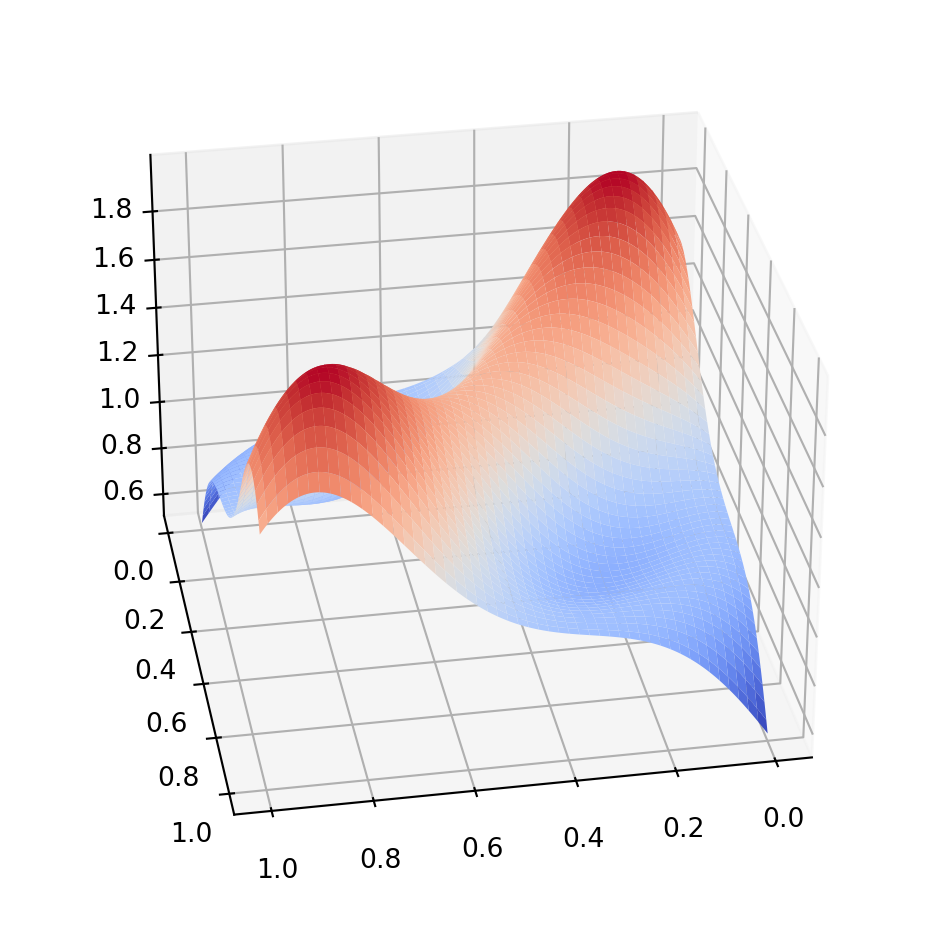
import matplotlib.pyplot as pltfrom matplotlib import cmimport numpy as npx = np.linspace(0, 1, 200)y = np.linspace(0, 1, 200)x, y = np.meshgrid(x, y)z = np.exp(-((x-1/2)**2+ (y-1/2)**2-1/4)**2*10) + np.exp(-(y-x)**2*10)fig, ax = plt.subplots(subplot_kw={'projection': '3d'})fig.set_size_inches(6,6)ax.view_init(30, 80)ax.plot_surface(x, y, z, cmap=cm.coolwarm)plt.show()
Figure 1: A complicated 2-dimensional function
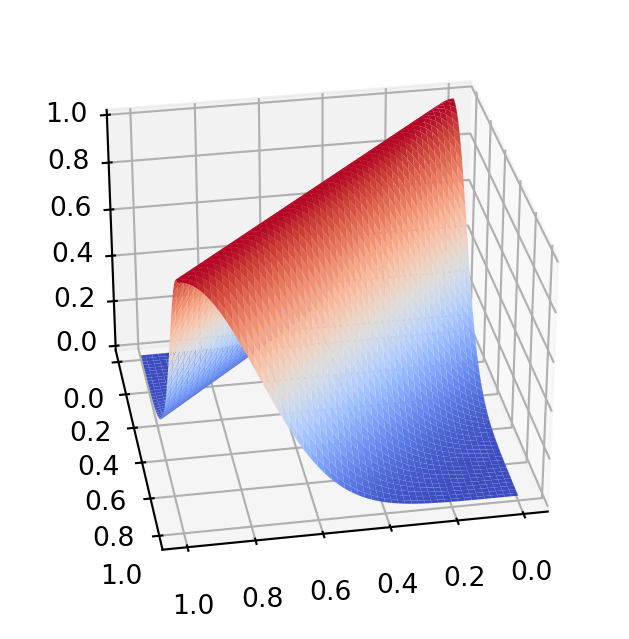
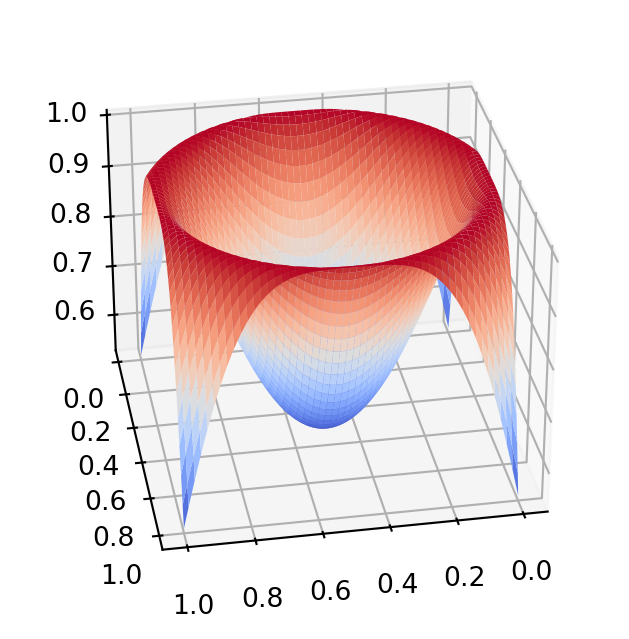
The Vegas grid may have trouble adapting to the enhancements of this function. One may integrate these integrals separately, so that the grid can adapt. Below you can see the two summands of the complicated function above:
Code
import matplotlib.pyplot as pltfrom matplotlib import cmimport numpy as npx = np.linspace(0, 1, 200)y = np.linspace(0, 1, 200)x, y = np.meshgrid(x, y)z = np.exp(-(y-x)**2*10)fig, ax = plt.subplots(subplot_kw={'projection': '3d'})fig.set_size_inches(8,4)ax.view_init(30, 80)ax.plot_surface(x, y, z, cmap=cm.coolwarm)plt.show()plt.show()import matplotlib.pyplot as pltfrom matplotlib import cmimport numpy as npx = np.linspace(0, 1, 200)y = np.linspace(0, 1, 200)x, y = np.meshgrid(x, y)z = np.exp(-((x-1/2)**2+ (y-1/2)**2-1/4)**2*10)fig, ax = plt.subplots(subplot_kw={'projection': '3d'})fig.set_size_inches(8,4)ax.view_init(30, 80)ax.plot_surface(x, y, z, cmap=cm.coolwarm)plt.show()
NoteSmarter coordinates
The reader may recognize that these two integrand are easier to integrate when doing additional coordinate transformations. The left integrand can be rotated to align with the axes, and the right integrand can be integrated using polar coordinates.
If one integrand is smaller than the other, this will waste quite some time, since we are only interested in the sum of them and the error on the sum. In Symbolica we can achieve the best of both worlds: we can first sample which integrand to sample from and then sample a point in the grid for that particular integrand.
This is done by creating a nested grid, where the first layer is discrete: it can only sample integral values. Each bin in the discrete grid may have a sub-grid, which is either another discrete grid or it is a continuous grid.
usesymbolica::prelude::*;fn main() {// define the two functionslet fs = [|x:f64| (-10.*(sample.c[1] - sample.c[0]).powi(2)).exp(),|x:f64| (-10.*((sample.c[0]-0.5).powi(2) + (sample.c[1]-0.5).powi(2) -0.25).powi(2)).exp()];letmut grid =DiscreteGrid::new(vec![Some(Grid::Continuous(ContinuousGrid::new(1,10,1000,None,false, ))),Some(Grid::Continuous(ContinuousGrid::new(1,10,1000,None,false, ))), ],0.01,false, );letmut rng =rand::thread_rng();letmut sample =Sample::new();for iteration in1..20{// sample 10_000 times per iterationfor _ in0..10_000{ grid.sample(&mut rng,&mut sample);ifletSample::Discrete(_weight, i, cont_sample) =&sample {ifletSample::Continuous(_cont_weight, xs) = cont_sample.as_ref().unwrap().as_ref(){ grid.add_training_sample(&sample, fs[*i](xs[0])).unwrap();}}} grid.update(1.5);println!("Integral at iteration {:2}: {:.6} ± {:.6}", iteration, grid.accumulator.avg, grid.accumulator.err );}}
Advanced options
Custom loops
For large production numerical integrations more flexibility than what a callback function provides is desirable. Symbolica allows users to do manual updating:
The user is in full control over the number of iterations, early termination, the number of samples per iteration, update rates, etc. It is also easier to parallelize the calling of the integrand or distribute the evaluations over multiple computers.
Integrator weights
Each sample provides the integrator weights (related to the bin size) for every layer. This can be used to study enhancements.
Maximal points
The statistics accumulator keeps track of which input yielded the maximum absolute value. These points are important for the health of the numerical integration: one accidentally large sample point may need many samples to cancel out and may leave a bias. They can be accessed with
The function you may be integrating may not yield a single number, but may yield a complex number of a vector for example. The grids only train on a single numerical value, so the user has to transform this output to a single number. It is possible to gain an estimate of the other output quantities, by tracking them with a StatisticsAccumulator, similar to how the grids track the current average and error. In the example below we have a function that yields a complex number. We train on the real part, and use the imaginary_part statistics accumulator to also track our estimate of the imaginary part.
Integral at iteration 1: 0.841742 ± 0.001388 + 0.459051i ± 0.002480i
Integral at iteration 2: 0.841655 ± 0.000249 + 0.441910i ± 0.001739i
Integral at iteration 3: 0.841404 ± 0.000158 + 0.434650i ± 0.001418i
Integral at iteration 4: 0.841497 ± 0.000124 + 0.430370i ± 0.001224i
Integral at iteration 5: 0.841528 ± 0.000105 + 0.427358i ± 0.001093i
Integral at iteration 6: 0.841522 ± 0.000093 + 0.426272i ± 0.000996i
Integral at iteration 7: 0.841488 ± 0.000084 + 0.425597i ± 0.000922i
Integral at iteration 8: 0.841529 ± 0.000077 + 0.424597i ± 0.000862i
Integral at iteration 9: 0.841485 ± 0.000072 + 0.424339i ± 0.000811i
Integral at iteration 10: 0.841443 ± 0.000068 + 0.424220i ± 0.000770i
The error on the imaginary part is larger, which is to be expected since we are not training to minimize this error. Furthermore, for this particular function, \(\cos(x) + i \sin(x)\), the enhanced regions of the real part are misaligned with the ones from the imaginary part.
Running on HPC clusters
Often one wants to run a numerical integration in parallel on a cluster. The following setup can be used:
The master node keeps track of the grid and initializes the random number generators in the workers with the same seed but different thread ID
For every iteration:
The master sends a serialized version of the current grid to the workers
The workers generate independent sample points, evaluate the sample points and add the training samples to the grid
The worker serializes the grid and sends it back to the master
The master merges all grids into the main one and updates the grid
By sending the grid (optionally compressed) instead of the samples, the data transfer can be kept to a minimum.

 Python
Python Rust
Rust